
Predicting credit risk when data is scarce can be challenging. Transfer learning offers a solution by leveraging patterns from data-rich domains to improve predictions in data-scarce ones. This approach is helping financial institutions assess risks more accurately, especially for underserved groups and small businesses with limited credit histories.
Key Takeaways:
- What is Transfer Learning? It reuses knowledge from one domain (e.g., credit card lending) to improve predictions in another (e.g., small business loans).
- Why It Matters: It addresses data scarcity, improves risk management and model accuracy (e.g., a 10.7% boost in Gini coefficient in some cases), and expands credit access for underserved groups.
- Challenges: Domain mismatch, bias transfer, and regulatory compliance are key hurdles.
- Applications: Cross-country risk assessments, MSME lending, and adapting to economic shifts.
Transfer learning is reshaping credit risk modeling by bridging the gap between data-rich and data-poor scenarios, enabling smarter, faster, and more inclusive lending decisions.
Cikla & Zhutovsky - Transfer Learning in Boosting Models | PyData Amsterdam 2023
How to Apply Transfer Learning in Default Risk Models
Applying transfer learning to default risk models requires careful planning, from selecting the right domains to aligning features and ensuring the model remains transparent. Each step is crucial for achieving accurate predictions and maintaining trust in the system. Let’s break it down.
Choosing Source and Target Domains
The first step is identifying source domains with plenty of high-quality data and target domains where data is limited but precise risk predictions are critical. The trick is finding domains that share meaningful financial behavior patterns, even if the lending products differ. For instance, credit card lending, often analyzed when comparing Mezzi vs Personal Capital, provides a wealth of data with transferable insights into consumer financial habits.
When evaluating domain pairs, consider similarities in financial behavior, demographics, and economic conditions. For example, a model trained on urban credit card users may struggle when applied to rural small business lending due to vastly different economic environments. On the other hand, products like personal loans and debt consolidation loans often share enough common ground to make knowledge transfer effective.
Feature Alignment and Domain Adaptation
After selecting the domains, the next step is aligning features to ensure the knowledge transfer works seamlessly. This involves creating representations that highlight essential patterns while filtering out domain-specific noise. Techniques like Wasserstein distance and domain adversarial networks can help align feature distributions. For example, the FDAT model improved prediction accuracy by 3.5% using such methods.
To extract domain-invariant features and prevent overfitting - especially when target data is scarce - adversarial training and regularization during fine-tuning are effective strategies. Proper feature alignment not only boosts performance but also makes the model easier to understand, which leads us to the next critical aspect: explainability.
Making AI Models Explainable in Transfer Learning
Explainability is a cornerstone of transfer learning, especially in sensitive areas like lending. Stakeholders and regulators need to understand both the predictions and how information from one domain influences outcomes in another. Tools like the Shapley framework can quantify feature contributions, helping to identify biases and promote fairer lending practices. This transparency ensures that key features remain relevant across domains, while also revealing any bias introduced during the adaptation process.
Clear explanations are also essential for regulatory compliance. For example, the European Union’s General Data Protection Regulation (GDPR) requires providing "meaningful information about the logic involved" in automated decisions. Historical cases, such as the bias found in the COMPAS tool in the United States, highlight the importance of regular audits to address potential fairness issues.
Benefits and Drawbacks of Transfer Learning in Default Risk Models
Transfer learning brings exciting possibilities to credit risk assessment, but it also comes with its share of challenges. We’ll dive into the pros and cons to help you understand when this approach might be the right fit.
Main Benefits
One of the standout advantages of transfer learning is its ability to deliver better accuracy in situations where data is limited. For instance, experiments with Lending Club showed that transfer learning models improved the Gini coefficient by 10.7% (0.301 compared to traditional models). This is a big deal in environments where data scarcity can hinder the performance of standard models.
Another major win is its potential to widen financial access. A Bankrate survey revealed that 58% of millennials in the U.S. have been denied at least one financial product due to their credit score. Transfer learning can help bridge this gap, addressing the $5.2 trillion MSME financing shortfall by enabling more accurate risk assessments for individuals and businesses that conventional credit scoring methods often overlook.
Additionally, transfer learning can save significant time during model training. Instead of building a new model for every lending product, pre-trained models can be reused, speeding up the process. However, these benefits don’t come without hurdles.
Common Problems and Limitations
Despite its advantages, transfer learning isn’t without its challenges. One key issue is domain mismatch. If the source and target domains differ too much, the model might experience negative transfer, where performance actually worsens. Economic differences between regions or markets can heavily influence how well a model transfers.
Bias transfer is another concern. A model trained on biased data in the source domain could carry those biases into the target domain, potentially perpetuating unfair lending practices. This makes regular audits and oversight critical to ensure compliance with fair lending regulations, similar to how AI tools for estate tax compliance streamline complex regulatory requirements.
Regulatory compliance also becomes trickier. Many jurisdictions require models to be explainable, but explaining decisions based on knowledge from multiple domains is far more complicated than single-domain models.
Finally, feature alignment issues can undermine the effectiveness of transfer learning. Differences in features between the source and target domains need careful handling - tools like the Kolmogorov-Smirnov test are often used to ensure that transferred knowledge is applied appropriately.
Comparison Table: Transfer Learning vs. Standard Models
| Aspect | Transfer Learning | Standard Models |
|---|---|---|
| Data Requirements | Uses source domain data when target data is limited | Needs substantial historical data in the target domain |
| Accuracy in Low-Data | 10.7% Gini coefficient improvement | Struggles with insufficient data |
| Training Time | Quicker with pre-trained models | Slower, as models are built from scratch |
| Interpretability | Complex, multi-domain explanations required | Simpler, single-domain decisions |
| Regulatory Compliance | Cross-domain knowledge attribution is challenging | Straightforward feature attribution |
| Bias Risk | Higher risk due to source domain bias transfer | Limited to biases in the target domain |
| Implementation Complexity | High; requires domain adaptation | Lower; follows standard ML pipeline |
| Financial Inclusion Impact | Improves access for underserved groups | Limited by reliance on historical data |
For institutions stepping into new lending markets with little target data, transfer learning can be a game-changer, even if it adds complexity. On the other hand, if you have plenty of historical data and need a simpler regulatory path, traditional models might be the better choice.
"Although the percentage improvements are small, such improvements in real world lending could be of significant economic importance." - Hendra Suryanto et al.
Understanding these trade-offs is key to tailoring models for practical use.
Practical Uses of Transfer Learning in Default Risk Models
Transfer learning is making waves in credit risk assessments by enabling better decisions, even when historical data is scarce.
Use Cases in Financial Lending
Cross-Country Risk Assessment
A study by Li et al. demonstrated how data from the US and China could be combined to predict default probabilities for Chinese firms. By employing domain adaptation with deep neural networks to align datasets from these two markets, the framework outperformed models that relied solely on local data. This method allows financial institutions to tap into existing market insights, enabling quicker and more informed lending decisions in unfamiliar regions without waiting to gather extensive local data.
Cross-Industry Credit Enhancement
Wang et al. tackled the challenge of using credit risk models across different industries. By utilizing data from the manufacturing sector to improve predictions in the service industry, they employed generative adversarial networks to create synthetic data tailored to the target industry. This approach outperformed traditional models, offering a way for lenders to diversify their loan portfolios while maintaining effective risk management.
Temporal Transfer for Economic Shifts
Chen et al. developed a framework to improve credit risk forecasting during the post-COVID-19 period by leveraging pre-pandemic data. Their use of temporal attention and domain adaptation helped bridge time-related discrepancies, resulting in more accurate and stable predictions.
MSME and Underbanked Lending
Micro, Small, and Medium Enterprises (MSMEs) often face challenges due to limited credit data. Transfer learning has proven effective in this area, improving default prediction accuracy. For instance, experiments revealed a 10.7% boost in the Gini coefficient for MSME default predictions. This advancement helps address gaps in lending to underbanked sectors.
These examples highlight how transfer learning can revolutionize credit risk modeling by extending its application across regions, industries, and economic conditions.
Steps to Deploy Transfer Learning in Production
To fully realize the benefits of transfer learning in credit risk assessments, it’s essential to follow a systematic credit risk modeling process.
Data Collection and Preprocessing
Start by gathering and cleaning data from both the source and target domains. Ensure consistency in data quality and address missing values properly.
Model Selection and Architecture Design
Choose models based on the nature of your data and regulatory requirements. For structured data, enhance traditional models like logistic regression or decision trees, while deep learning models are better suited for unstructured data.
Domain Adaptation Implementation
Use statistical tests, such as the Kolmogorov-Smirnov test, to measure differences between source and target data. Adjust features to align the datasets, ensuring that critical predictive elements are retained.
Training and Validation Processes
Divide data into training and testing sets from both domains. Train the model and validate it using metrics like accuracy, precision, recall, and F1-score. Employ cross-validation to reduce the risk of overfitting.
Production Deployment Infrastructure
Set up pipelines capable of processing features from both domains in real time. Deploy models using REST APIs to ensure seamless integration.
Monitoring and Continuous Improvement
Keep a close eye on model performance and monitor how the domains interact over time. Use feedback loops to trigger retraining when economic conditions or regulations change. Maintain audit trails to ensure transparency and explainability.
How Mezzi Uses AI and Transfer Learning for Better Risk Assessment
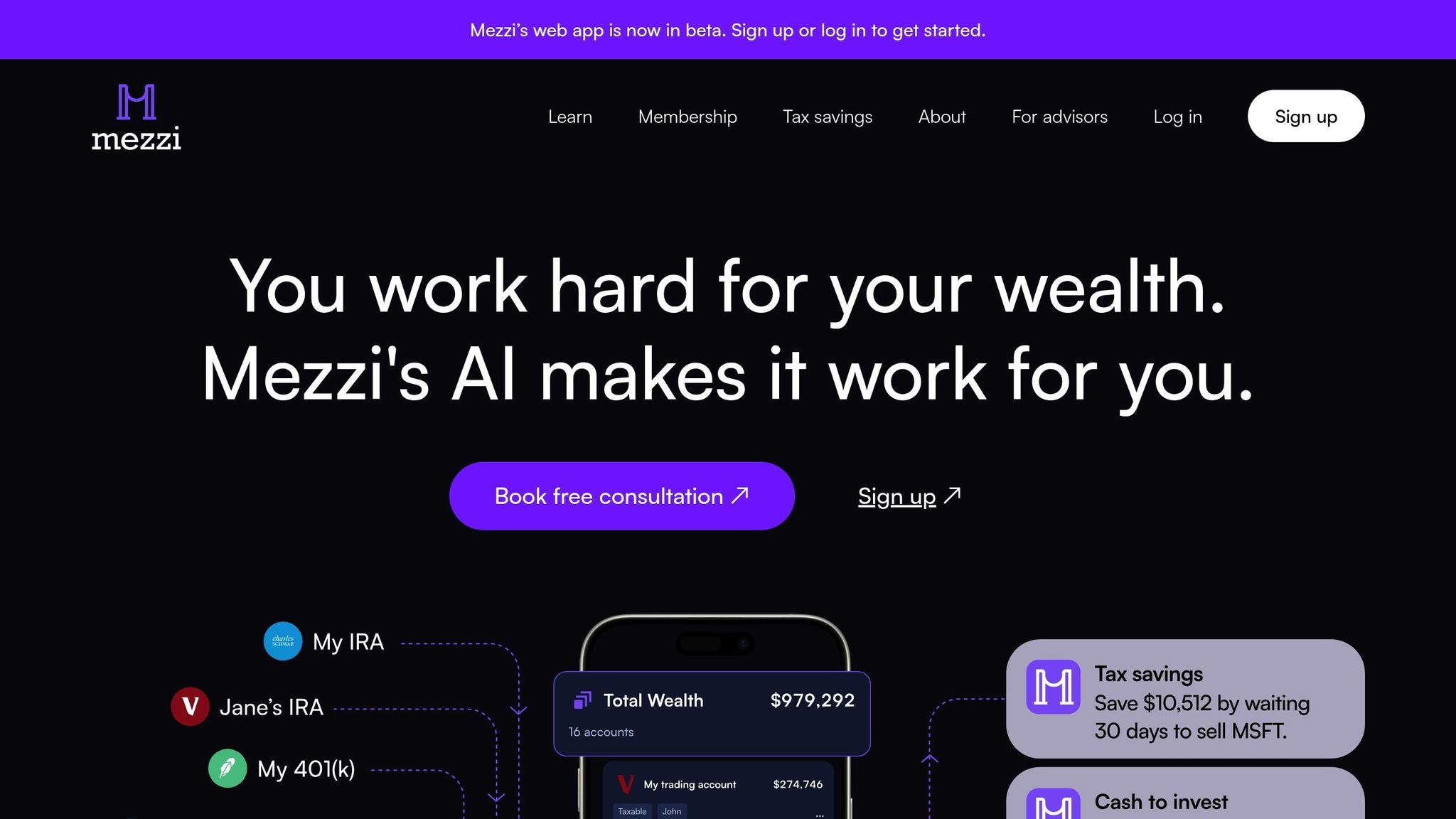
Mezzi's platform showcases how cutting-edge financial technology can harness AI and transfer learning to provide advanced risk assessments - tools that were once accessible only through costly financial advisors. By simplifying complex financial data into actionable insights, Mezzi empowers users to make informed investment choices and refine their wealth-building strategies. This approach highlights how transfer learning not only improves traditional risk models but also helps investors navigate financial uncertainties with greater confidence.
Mezzi's AI-Powered Platform
Mezzi's AI system goes far beyond AI-enhanced account aggregation. It pulls data from multiple financial sources to create a unified, actionable financial overview. This consolidated approach allows the platform's AI to uncover patterns, identify risks, and spot opportunities that would be nearly impossible to detect manually.
This capability reflects the transformative impact of AI in the financial sector. According to McKinsey, AI technologies could add up to $1 trillion in value annually to global banking. Mezzi brings this level of sophistication to individual investors with features like real-time monitoring, which helps optimize tax strategies and prevent wash sales across multiple accounts. By tracking transactions as they happen and flagging potential wash sale violations, the platform provides timely alerts, minimizing the risk of costly tax errors.
Another standout feature is Mezzi's X-Ray tool, which uncovers hidden risks within investment portfolios. By analyzing holdings across all connected accounts, it identifies duplicate exposures and concentration risks that might otherwise go unnoticed. This is especially helpful for active investors juggling multiple portfolios. The insights provided by X-Ray offer a level of risk analysis typically reserved for professional portfolio managers. On top of this, Mezzi leverages transfer learning to refine its risk assessments even further.
Transfer Learning for Smarter Investment Strategies
Mezzi uses transfer learning to enhance the precision of its risk assessments, particularly for users with limited investment histories or those exploring new markets. By applying knowledge from established market patterns and similar investment scenarios, the AI can make more accurate predictions. It draws on insights from comparable strategies across different market conditions and user profiles, improving its ability to assess risks.
This approach is particularly relevant when considering the estimated $5.2 trillion financing gap for MSMEs in developing nations, which is 1.4 times the current level of MSME lending. Features like the Financial Calculator benefit from transfer learning by incorporating data from similar user profiles, historical trends, and market conditions. This enables the platform to deliver more realistic retirement and long-term planning projections, factoring in variables like asset manager fees and market volatility. Additionally, transfer learning allows Mezzi to provide tailored insights as users move through different investment phases, drawing on the experiences of others who have successfully navigated similar transitions.
While these advanced AI capabilities are impressive, they also demand stringent data security measures.
Security and Privacy in AI-Powered Financial Platforms
Mezzi understands that data security and privacy are critical concerns when deploying AI in financial services. To address these challenges, the platform incorporates multiple layers of protection to safeguard user data throughout the AI process while still enabling advanced analysis.
To ensure privacy, Mezzi employs technologies like differential privacy and data anonymization, which protect individual data while enabling meaningful insights. The platform also offers an ad-free experience, reinforcing its commitment to user privacy.
Additionally, Mezzi secures its AI supply chain by monitoring dependencies, validating data sources, and adhering to Zero-Trust security principles. Measures such as encrypted model storage and execution, strict access controls, and output randomization help shield against unauthorized access, adversarial attacks, model inversion, and data leaks. These safeguards ensure that users can benefit from the platform's advanced features without compromising their data security.
Conclusion: Changing Default Risk Assessment with Transfer Learning
Transfer learning is transforming how financial institutions evaluate credit risk, especially in situations where historical data is sparse. Traditional credit models often struggle in new or underserved markets, but transfer learning steps in by utilizing existing data to make accurate predictions in these data-limited environments.
For instance, a simulation by LendingClub revealed that using credit card and debt consolidation data to forecast small business loan defaults boosted the Gini coefficient by 10.7% (from 0.272 to 0.301). This improvement directly addresses the challenges of insufficient historical data while tackling the $5.2 trillion financing gap for micro, small, and medium enterprises (MSMEs).
Although the percentage increase might seem small, the impact is anything but. When applied across millions of loan decisions, these enhancements can significantly lower default rates and expand access to credit for borrowers who were previously overlooked.
Building on these advancements, Mezzi has illustrated how transfer learning can enhance risk assessment by identifying similar patterns across markets. This technology powers tools like the X-Ray for portfolio risk analysis and the Financial Calculator for realistic retirement planning, enabling more precise financial decision-making.
However, as the financial sector increasingly relies on sensitive data, robust security measures are critical. With the average cost of a data breach now at $4.88 million, strategies like differential privacy, data anonymization, and Zero-Trust security principles are indispensable for protecting financial information.
FAQs
How does transfer learning enhance credit risk assessment for small businesses with limited credit histories?
Transfer learning is transforming how credit risk is assessed for small businesses. By leveraging insights from existing models and data in related financial domains, this method addresses the challenge of limited credit history, allowing for more accurate predictions.
When combined with alternative data sources, alongside traditional credit evaluation methods, transfer learning boosts the reliability of risk models. This approach minimizes the effects of data scarcity and ensures small businesses receive fairer and more precise credit evaluations.
What challenges do financial institutions encounter when using transfer learning for default risk prediction?
Financial institutions encounter a variety of hurdles when applying transfer learning to default risk models. One of the biggest challenges lies in handling data differences between the source and target domains. For example, shifts in data distribution or changes in the importance of certain features can disrupt the effectiveness of transfer learning if not addressed properly.
Another significant obstacle is maintaining model reliability in diverse financial environments. Market conditions and borrower behaviors can vary widely, making it tough to ensure consistent performance. On top of that, access to high-quality datasets is often limited, which can make training and adapting models more difficult. To tackle these issues, institutions need to focus on meticulous data preprocessing, leverage domain expertise, and continuously validate their models to deliver dependable results.
How does transfer learning support regulatory compliance in credit risk modeling?
Transfer learning plays a key role in keeping credit risk models aligned with evolving regulations. By enabling models to adjust to new data and regulatory changes without needing a complete retraining, it helps maintain both accuracy and compliance. This adaptability ensures that predictions stay reliable while meeting updated standards.
Another advantage of transfer learning is its ability to draw on the knowledge of existing models. This can help minimize bias and make decision-making processes more transparent - two factors that are crucial for regulatory compliance. Beyond saving time and resources, this approach promotes a stronger and more ethical foundation for assessing credit risk.
Related Blog Posts
Table of Contents
Book Free Consultation
Walk through Mezzi with our team, review your current situation, and ask any questions you may have.